14 Books by P99 CONF Speakers: Latency, Wasm, Databases & More


P99 CONF 2024 speakers have amassed a rather impressive list of publications, including quite a few books. This blog highlights 14 of them.
P99 CONF 2024 speakers have amassed a rather impressive list of publications, including quite a few books. This blog highlights 14 of them.
Get to know Chris Riccomini (Materialized View) in anticipation of his P99 CONF talk: “Building a Cloud Native LSM on Object Storage” with Rohan Desai.
If you share our obsession with high-performance low-latency data systems, here’s a rundown of sessions to consider joining at P99 CONF 2024.
Get to know Gunnar Morling, Senior Staff Software Engineer at Decodable, in anticipation of his P99 CONF talk: “1BRC – Nerd Sniping the Java Community”
Whether you can’t wait for P99 CONF 2024 or you’re still debating whether to attend, now’s a great time to binge-watch the 150+ tech talks available in our on-demand library. If you’re not sure where to start, here’s a rundown of the most popular sessions to date.
Get to know Cameron Morgan, Staff Infrastructure Engineer at Shopify, in anticipation of his P99 CONF talk: “Reliable Data Replication”
A (somewhat) friendly P99 CONF popup debate with Jarred Sumner (Bun.js), Pekka Enberg (Turso) and Glauber Costa (Turso) on ThePrimeagen
How data is replicated to support low latency for ZeroFlucs’ global usage patterns – without racking up unnecessary costs
ZeroFlucs’ business – processing sports betting data – is rather latency sensitive. Content must be processed in near real-time, constantly, and in a region local to both the customer and the data. And there’s incredibly high throughput and concurrency requirements – events can update dozens of times per minute and each one of those updates triggers tens of thousands of new simulations (they process ~250,000 in-game events per second).
At ScyllaDB Summit, ZeroFlucs’ Director of Software Engineering Carly Christensen walked attendees through how ZeroFlucs provides optimized data storage local to the customer – including how their recently open-sourced Golang ScyllaDB helper library (cleverly named Charybdis) facilitates this.
This blog post, based on that talk, shares their brilliant approach to figuring out exactly how data should be replicated to support low latency for their global usage patterns without racking up unnecessary storage costs.
Join us at P99 CONF 24 to hear more firsthand accounts of how teams are tackling their toughest database challenges. Disney, Shopify, Uber, LinkedIn, American Express, Netflix, and more are all on the agenda.
First, a little background on the business challenges that the ZeroFlucs technology is supporting. ZeroFlucs’ same-game pricing lets sports enthusiasts bet on multiple correlated outcomes within a single game. This is leagues beyond traditional bets on what team will win a game and by what spread. Here, customers are encouraged to design and test sophisticated game theories involving interconnected outcomes within the game. As a result, placing a bet is complex, and there’s a lot more at stake as the live event unfolds.
For example, assume there are three “markets” for bets:

Someone could place a bet on team A to win, B. Bhooma to score the first touchdown, and for the total score to be under 45.5 points. If you look at those 3 outcomes and multiply the prices together, you get a price of around $28. But in this case, the correct price is approximately $14.50.
Carly explains why. “It’s because these are correlated outcomes. So, we need to use a simulation-based approach to more effectively model the relationships between those outcomes. If a team wins, it’s much more likely that they will score the first touchdown or any other touchdown in that match. So, we run simulations, and each simulation models a game end-to-end, play-by-play. We run tens of thousands of these simulations to ensure that we cover as much of the probability space as possible.”
The ZeroFlucs platform was designed from the ground up to be cloud native. Their software stack runs on Kubernetes, using Oracle Container Engine for Kubernetes. There are 130+ microservices, growing every week. And a lot of their environment can be managed through custom resource definitions (CRDs) and operators. As Carly explains, “For example, if we want to add a new sport, we just define a new instance of that resource type and deploy that YAML file out to all of our clusters.” A few more tech details:
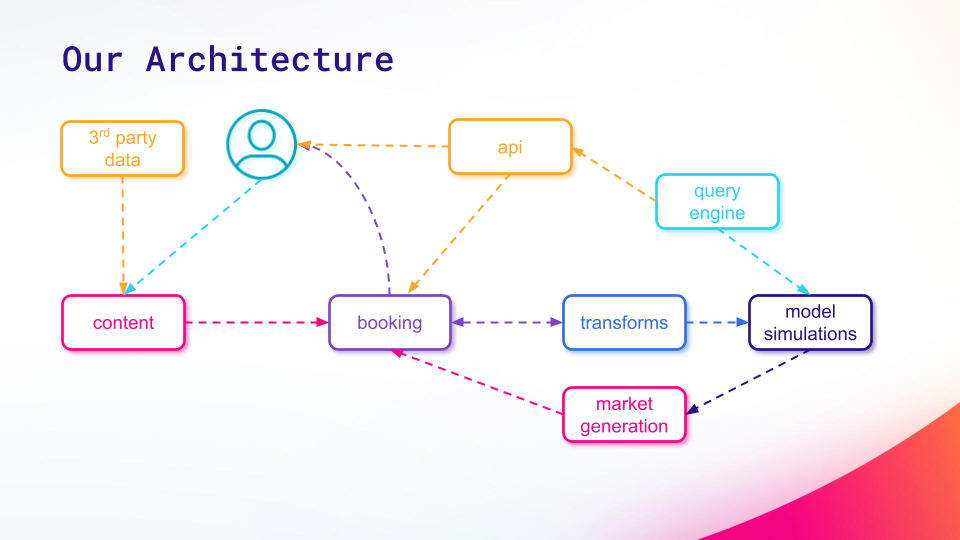
As the diagram above shows:
Any content update starts the entire process over again.
ZeroFlucs’ ultimate goal is to process and simulate events fast enough to offer same-game prices for live in-play events. For example, they need to predict whether this play results in a touchdown and which player will score the next touchdown – and they must do it fast enough to provide the prices before the play is completed. There are two main challenges to accomplishing this:
Carly and team initially explored whether three popular databases might meet their needs here.
Then they thought about ScyllaDB, a database they had discovered while working on a different project. It didn’t make sense for the earlier use case, but it met this project’s requirements quite nicely. As Carly put it: “ScyllaDB supported the distributed architecture that we needed, so we could locate our data replicas near our services and our customers to ensure that they always had low latency. It also supported the high throughput and concurrency that we required. We haven’t yet found a situation that we couldn’t just scale through. ScyllaDB was also easy to adopt. Using ScyllaDB Operator, we didn’t need a lot of domain knowledge to get started.”
ZeroFlucs is currently using ScyllaDB hosted on Oracle Cloud Flex 4 VMs. These VMs allow them to change the CPU and memory allocation to those nodes if needed. It’s currently performing well, but the company’s throughput increases with every new customer. That’s why they appreciate being able to scale up and run on bare metal if needed in the future.
They’re already using ScyllaDB Operator to manage ScyllaDB, and they were reviewing their strategy around ScyllaDB Manager and ScyllaDB Monitoring at the time of the talk.
To make the most of ScyllaDB, ZeroFlucs divided their data into three main categories:
Carly shared an example: “Just to illustrate that idea, let’s say we have a customer in London. We will place a copy of our services (“a cell”) into that region. And all of that customer’s interactions will be contained in that region, ensuring that they always have low latency. We’ll place multiple replicas of their data in that region. And will also place additional replicas of their data in other regions. This becomes important later.”
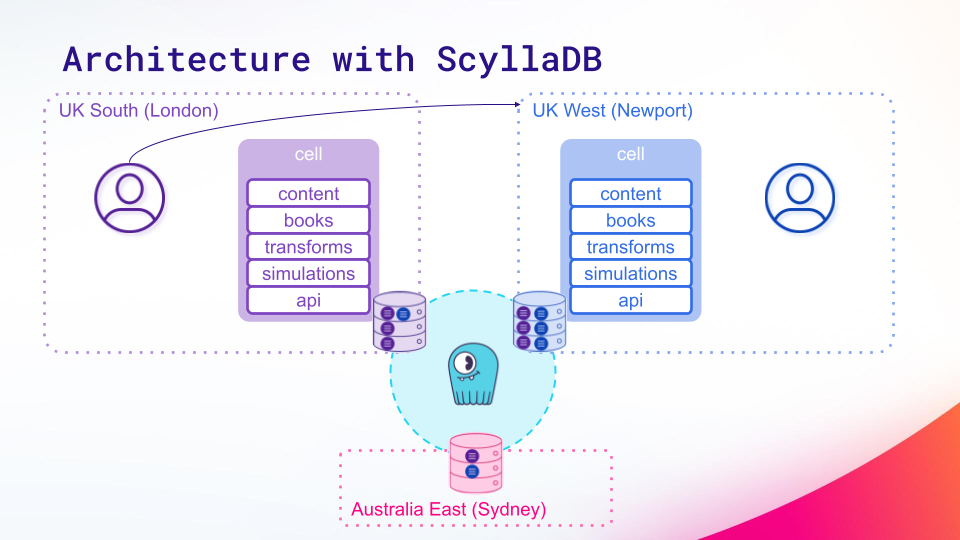
Now assume there’s a customer in the Newport region. They would place a cell of their services there, and all of that customer’s interactions would be contained within the Newport region so they also have low latency.
Carly continues, “If the London data center becomes unavailable, we can redirect that customer’s requests to the Newport region. And although they would have increased latency on the first hop of those requests, the rest of the processing is still contained within one data center – so it would still be low latency.” With a complete outage for that customer averted, ZeroFlucs would then increase the number of replicas of their data in that region to restore data resiliency for them.
ZeroFlucs separates data into services and keyspaces, with each service using at least one keyspace. Global data has just one keyspace, regional data has a keyspace per region, and customer data has a keyspace per customer. Some services can have more than one data type, and thus might have both a global keyspace as well as customer keyspaces.
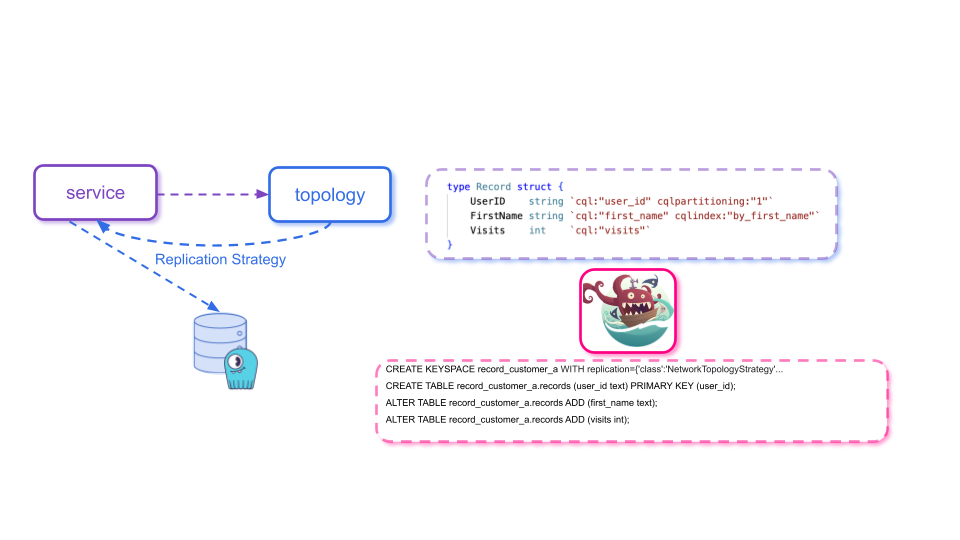
They needed a simple way to manage the orchestration and updating of keyspaces across all their services. Enter Charybdis, the Golang ScyllaDB helper library that the ZeroFlucs team created and open sourced. Charybdis features a table manager that will automatically create keyspaces as well as add tables, columns, and indexes. It offers simplified functions for CRUD-style operations, and it supports LWT and TTL.
Note: For an in-depth look at the design decisions behind Charybdis, see this blog by ZeroFlucs Founder and CEO Steve Gray.
There’s also a topology Controller Service that’s responsible for managing the replication settings and keyspace information related to every service.
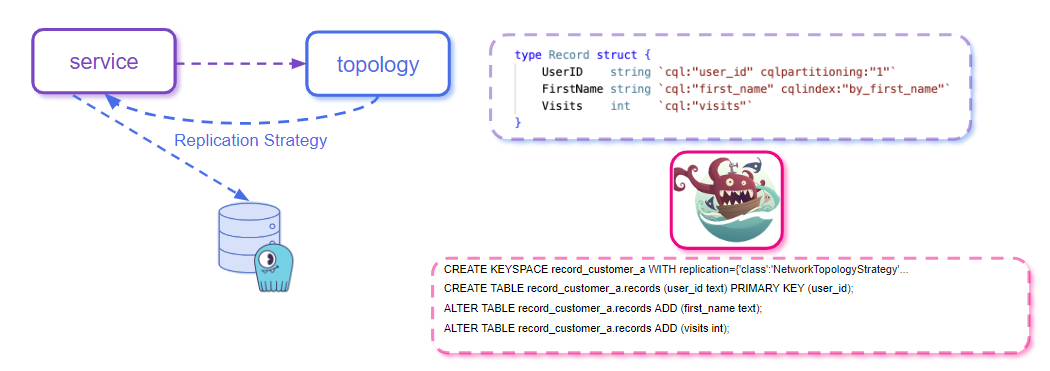
Upon startup, the service calls the topology controller and retrieves its replication settings. It then combines that data with its table definitions and uses it to maintain its keyspaces in ScyllaDB. The above image shows sample Charybdis-generated DDL statements that include a network topology strategy.
Carly concluded: “We still have a lot to learn, and we’re really early in our journey. For example, our initial attempt at dynamic keyspace creation caused some timeouts between our services, especially if it was the first request for that instance of the service. And there are still many Scylla DB settings that we have yet to explore. I’m sure that we’ll be able to increase our performance and get even more out of Scylla DB in the future.”
You can watch Carly’s complete tech talk and skim through her deck in our tech talk library.

Get to know Amos Wenger, writer and video maker (aka @fasterthanlime) , in anticipation of their P99 CONF talk: ,”Rust + io_uring + ktls: How Fast Can We Make HTTP?”
Get to know Tanel Poder, Performance Nerd at PoderC Consulting, in anticipation of his P99 CONF talk: “Using eBPF Off-CPU Sampling to See What Your Databases are Really Waiting For”